Predict-Trends-in-Startup-Investment
Oluwatomisin Bamidele
Predict-Trends-in-Startup-Investment
It is generally believed in the venture investment communities that the success probability of a start-up is about one-tenth, which conveys the view that the failure rate of the start-up is very high. Whether a start-up can obtain investment from investors is a key factor in its success and the prediction of investment is of great importance to learn more about this factor. Therefore, it is very valuable for companies to explore the information of some well-known venture capital investors and utilize it to do an analysis and prediction. In particular, it could tell start-ups how to deal with investors when they plan to make a round of financing.
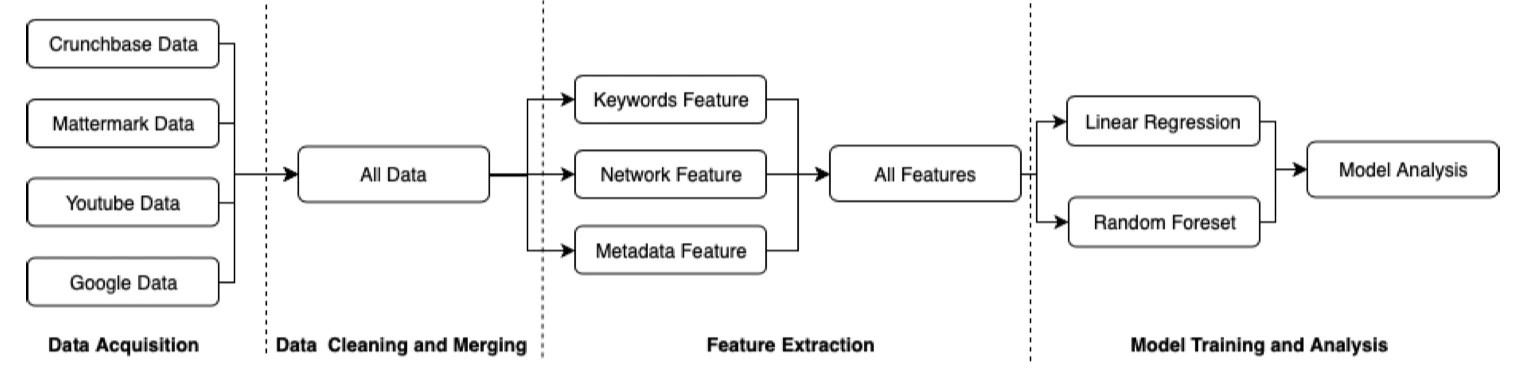
The goal of this project is to use multiple facets of the data science stack to analyze and predict whether investors will invest in some specified research domains and the amount of investment via his remarks (interviews or speeches). The report mainly consists of three simple parts: data acquisition, feature extraction, and model analysis. In the first part, it describes the process of scraping and cleaning data of some prominent VC investors, like Marc Andreessen, Peter Thiel, from different data sources. The second part is about extracting features including natural language processing features, network features, and metadata features from data and setting labels for them. In the final part, the report states the performance of supervised machine learning model used in the project, namely linear regression, and random forest and do an analysis based on the results.
The entire workflow of the project is as below:
Like this project
Posted Jul 14, 2024
Contribute to tomisi/Startup_Prediction development by creating an account on GitHub.
Likes
0
Views
20